Redis デザインと実装を読んでいると、スキップリスト(SkipList)に関連するアプリケーションがあることがわかりましたので、詳細を知りたいと思いました。以下に記録します。
スキップリストは、複数のリストを同時に維持するデータ構造です。つまり、クエリの速度を高速化するために、データを格納するためにより多くのスペースを使用することで、時間とのトレードオフを行っています。
構造は次のようになります:

構造#
通常のリストでは、次や前のようなポインタが他のノードを指すことがありますが、スキップリストはもっとすごいです。
スキップリストには、行(level、Redis のスキップリストノードのレベルの数は 1〜32)のようなポインタがあり、これらのポインタが通常異なる場所(スパン)を指します。
ノードの定義#
基本的なノードの属性は次のようになります。キーと値、および前方ポインタの数とそれらを保存する配列
public class Node<T> {
private Long key;
private T data;
private int level;
private Node<T>[] forwards;
}
データ構造#
SkipList の構造には、ヘッドノード、テールノード、およびノードを追加するときにノードの高さを提供する getRandomLevel() メソッドが含まれます。
public class SkipList<T> {
private int MAX_LEVEL;
private Node<T> head;
private Node<T> tail;
/**
* コンストラクタ
*
* @param level
*/
public SkipList(int level) {
}
/**
* 新しいノードのレベルを取得します。
* 最大ノード数を超えないようにします。
*
* @return
*/
public int getRandomLevel() {
int count = 0;
Random random = new Random(System.currentTimeMillis());
while (Math.abs(random.nextLong()) % 2 == 1) {
if (count < MAX_LEVEL - 1) {
count += 1;
} else {
break;
}
}
if (count > MAX_LEVEL - 1) {
count = MAX_LEVEL - 1;
}
return count;
}
}
データの追加#
データを追加する際のキーは、追加する位置の前のノードを見つけることですが、同時に複数のレベルの前のノードを維持することです。
Node<T>[] update = new Node[MAX_LEVEL];
Node<T> tempHead = head;
前のノードを保存するための配列と、ループ変数の一時変数
for (int i = MAX_LEVEL - 1; i >= 0; i--) {
if (tempHead.getForwards()[i] == tail || tempHead.getForwards()[i].getKey() > key) {
update[i] = tempHead;
} else {
while (tempHead.getForwards()[i] != tail && tempHead.getForwards()[i].getKey() < key) {
tempHead = tempHead.getForwards()[i];
}
if (tempHead.getForwards()[i] != tail && tempHead.getForwards()[i].getKey() == key) {
tempHead.getForwards()[i].setData(data);
return;
}
update[i] = tempHead;
}
}
最上位レベルからループし、最上位レベルはクロスするのが速いです。現在のノードの次のノードがテールであるか、キーが挿入するキーよりも大きい場合、現在のノードをこのレベルの結果として保存します。
保存したら、次のレベルに進みます。
上記の条件に合致しない場合は、そのレベルで横方向に進み続けます tempHead = tempHead.getForwards()[i]; テールであるか、キーが目標のキーよりも大きい場合まで。
そして、結果を保存します update[i] = tempHead;
最後にリストを更新します。
ノードを作成する際には、前方のレベル(level)が必要であり、level のサイズは Head のサイズを超えないようにする必要があります。また、level の値は確率に従っています。ここでは、
- 1 :1/2
- 2 :1/4
- 3 :1/8
- ..
level が増える確率は 1/2 です。
Redis では、level: 1/4 と MAX: 32 を使用しています。
Node<T> node = new Node<>();
node.setKey(key);
node.setData(data);
node.setForwards(new Node[level + 1]);
int level = getRandomLevel();
node.setLevel(level);
/**
* 新しいノードをリンクします。
*/
for (int i = 0; i <= level; i++) {
if (update[i] != null) {
node.getForwards()[i] = update[i].getForwards()[i];
update[i].getForwards()[i] = node;
}
}
検索#
検索と挿入はほぼ同じです。
横方向と縦方向にそれぞれループし、見つかったら返します。
public T getData(Long key) {
Node<T> tempHead = head;
for (int i = MAX_LEVEL - 1; i >= 0; i--) {
if (tempHead.getForwards()[i] == tail || tempHead.getForwards()[i].getKey() > key) {
continue;
} else {
while (tempHead.getForwards()[i] != tail && tempHead.getForwards()[i].getKey() < key) {
tempHead = tempHead.getForwards()[i];
}
if (tempHead.getForwards()[i] != null) {
if (tempHead.getForwards()[i].getKey() != null) {
if (tempHead.getForwards()[i].getKey().equals(key)) {
return tempHead.getForwards()[i].getData();
}
}
}
}
}
return null;
}
複雑さ#
各ノードの前方の高さはランダムなため、計算が非常に難しいです。
時間の複雑さ#
- 最悪の場合は O (n)
- 検索の確率は O (log n) が高いです
空間の複雑さ#
- S < 2n
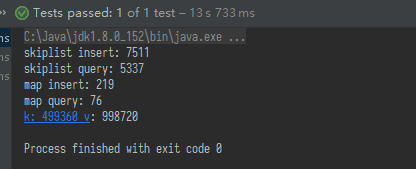
パフォーマンスの差#
Java の HashMap と比較してみましたが(膨張)、完全に負けました。