在看《Redis 设计与实现》的时候看到有涉及跳表(SkipList)的相关应用,就想了解一下。作记录如下。
跳表其实就是一个同时维护多条链表的数据结构。换句话说,就是为了加快查询速度,而占用更多的空间来储存数据,算是空间换时间了。
结构看起来是这样的:

结构#
在一般的链表里,会有 next 或这 forward/backward 这类的指针来指向其他节点,跳表
就厉害了
它有一排(level,redis 中跳表节点的 level 的数量是 1~32)这种指针,而且这些指针指向的节点的位置一般也不同(跨度不一样)。
节点定义#
一个最基本的节点的属性是这样的。Key 和 Value,以及前向指针的数量和保存他们的数组
public class Node<T> {
private Long key;
private T data;
private int level;
private Node<T>[] forwards;
}
数据结构#
SkipList 的结构包括头尾节点、最大的 level 高度,添加节点时,节点的高度由 getRandomLevel()方法提供
public class SkipList<T> {
private int MAX_LEVEL;
private Node<T> head;
private Node<T> tail;
/**
* 构造函数
*
* @param level
*/
public SkipList(int level) {
}
/**
* 获取新节点的层数,
* 不大于最大节点
*
* @return
*/
public int getRandomLevel() {
int count = 0;
Random random = new Random(System.currentTimeMillis());
while (Math.abs(random.nextLong()) % 2 == 1) {
if (count < MAX_LEVEL - 1) {
count += 1;
} else {
break;
}
}
if (count > MAX_LEVEL - 1) {
count = MAX_LEVEL - 1;
}
return count;
}
}
添加数据#
添加数据的关键在于,找到添加的位置的前置节点,而且是,同时维护的这么多层的前置节点。
Node<T>[] update = new Node[MAX_LEVEL];
Node<T> tempHead = head;
一个用来保存前置节点的数组,和临时变量用于遍历
for (int i = MAX_LEVEL - 1; i >= 0; i--) {
if (tempHead.getForwards()[i] == tail || tempHead.getForwards()[i].getKey() > key) {
update[i] = tempHead;
} else {
while (tempHead.getForwards()[i] != tail && tempHead.getForwards()[i].getKey() < key) {
tempHead = tempHead.getForwards()[i];
}
if (tempHead.getForwards()[i] != tail && tempHead.getForwards()[i].getKey() == key) {
tempHead.getForwards()[i].setData(data);
return;
}
update[i] = tempHead;
}
}
从最高层开始遍历,最高层的跨越较快。当 当前节点的下一个节点是尾部或者 key 大于要插入的 key 时,将当前节点保存为这一层的结果。
保存完后进入下一层。
如果不符合上面的条件,就接着在那一层横向遍历 tempHead = tempHead.getForwards()[i];直到尾部或 key 大于目标 key,key 相等就覆盖然后提前返回。
然后保存结果 update[i] = tempHead;
最后更新链表
创建链表节点时,要由前向层数(level),
level 的大小不超过 Head 的大小,而且 level 的数值时按概率来的,这里是
- 1 :1/2
- 2 :1/4
- 3 :1/8
- ..
level 加一的概率是 1/2
redis 取的是 level: 1/4 和 MAX : 32
Node<T> node = new Node<>();
node.setKey(key);
node.setData(data);
node.setForwards(new Node[level + 1]);
int level = getRandomLevel();
node.setLevel(level);
/**
* 链接新节点
*/
for (int i = 0; i <= level; i++) {
if (update[i] != null) {
node.getForwards()[i] = update[i].getForwards()[i];
update[i].getForwards()[i] = node;
}
}
查找#
查找和插入差不多
横向和纵向分别遍历,找到就返回
public T getData(Long key) {
Node<T> tempHead = head;
for (int i = MAX_LEVEL - 1; i >= 0; i--) {
if (tempHead.getForwards()[i] == tail || tempHead.getForwards()[i].getKey() > key) {
continue;
} else {
while (tempHead.getForwards()[i] != tail && tempHead.getForwards()[i].getKey() < key) {
tempHead = tempHead.getForwards()[i];
}
if (tempHead.getForwards()[i] != null) {
if (tempHead.getForwards()[i].getKey() != null) {
if (tempHead.getForwards()[i].getKey().equals(key)) {
return tempHead.getForwards()[i].getData();
}
}
}
}
}
return null;
}
复杂度#
由于每个节点的前向高度都是随机的,所以比较难算。
时间复杂度#
- 最差是 O (n)
- 查找 O (lgn) 的概率较高
空间复杂度#
- S < 2n
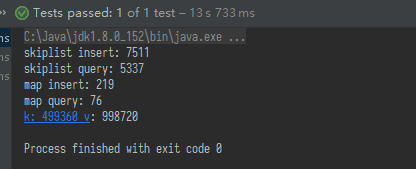
被吊打#
和 java 的 HashMap 比了一下(膨胀), 被吊打了